源码敬请参见:https://github.com/AlanCui4080/ThCattus/blob/master/therm_v1_processor.v
概论
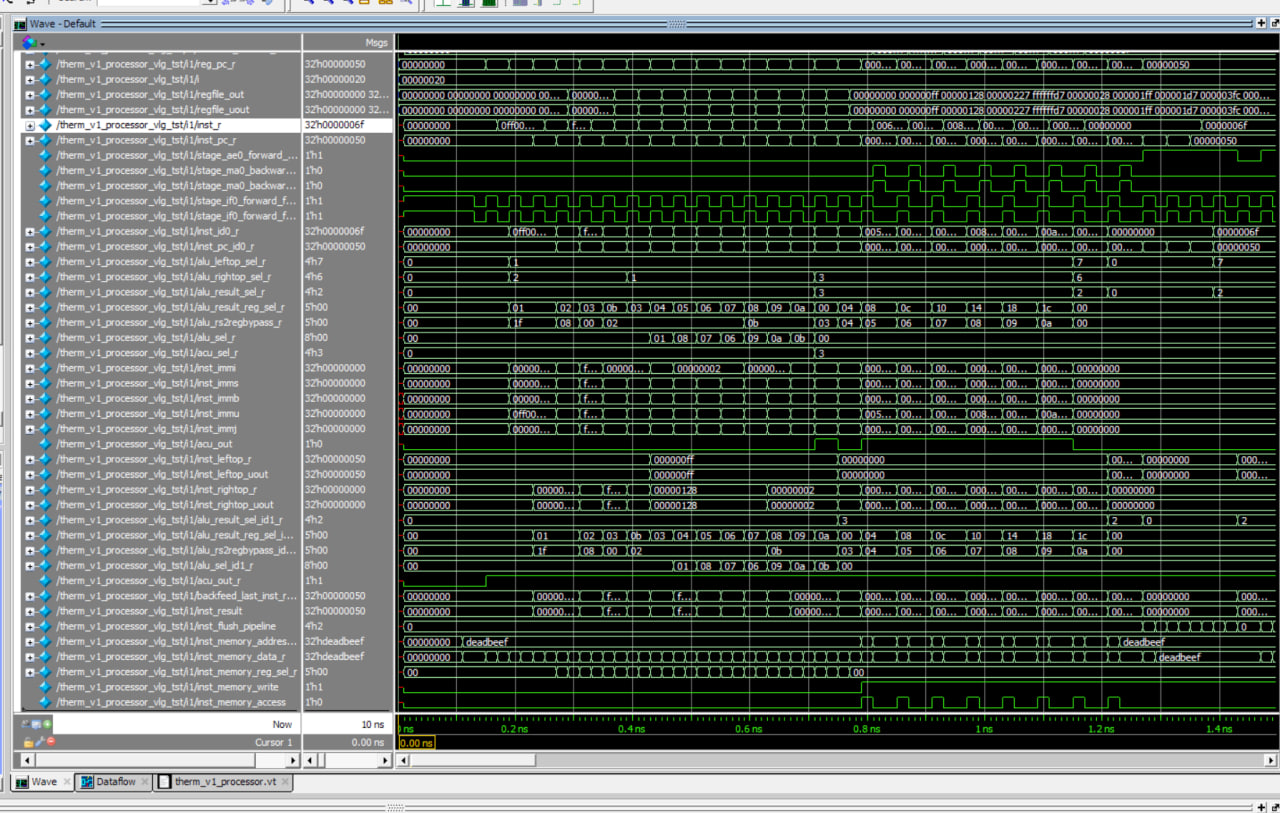
处理器使用精简的AHB作为接口,对外表现为哈佛架构,实现的RISC-V子集仅包括I,并且未实现非整字宽的Load/Store。整个执行流分为五级,IF/ID/OF/EX/MWB,即:取指令、选通内核、取操作数(无论是立即数还是寄存器)和分支指令预比较旁通、内存寄存器写回。这是为使得每级间大小占用尽量均衡而做的。由于AHB总线非顺序传输的特性,取指访存将至少持续一个周期的空泡,因而该处理器每两个周期才能处理一条算术指令,每四周期处理一条访存指令。
性能表现
在Cyclone IV E EP4CE15 速度等级C8平台上以激进性能方式综合布线后,LUT4占用为3,899,最大时钟为76.17Mhz,在MAX 10 10M8 速度等级C8平台上以激进性能方式综合布线后,LUT4占用为3,928,最大时钟为77.59Mhz。(为了同后者对比,因为笔者没有该款FPGA,所以没有实际测试)在Artix 7 XC7A50T 速度等级-3平台上以默认方式综合布线后,LUT6占用为1,498,最大时钟为113.22Mhz。对比下面给出的VexRISCV,性能仍有较大差距(体积+83%、主频-52%、综合性能-77%)。推测差距为 1、寄存器堆未以BRAM的形式实现引起的较高LUT小号 2、数据选通逻辑过于冗杂,不但拖慢了系统时钟,也使得系统资源消耗更高 3、未对AHB实现顺序读取,导致一半的处理器周期被浪费掉。
VexRiscv small and productive (RV32I, 0.82 DMIPS/MHz) -> Artix 7 -> 232 MHz 816 LUT 534 FF
以下给出了ROM初始化汇编,其中0xf0000000是串口外设的写数据寄存器,由于没有实现串口就绪寄存器的地址空间映射,使用忙等待确保写数据成功,该忙等待的数值理论上可以工作到>2Ghz,因而无论如何移植都是安全的:
li x1,0xf0000000
li x2,0x6c6c6548
li x3,0x6f77206f
li x4,0x00646c72
li x10,0xfffff
sw x2,0(x1)
loop1:
addi x10,x10,-1
bnez x10,loop1
li x10,0xfffff
sw x3,0(x1)
loop2:
addi x10,x10,-1
bnez x10,loop2
li x10,0xfffff
sw x4,0(x1)
loop3:
addi x10,x10,-1
bnez x10,loop3
li x10,0xfffff
jal x0,0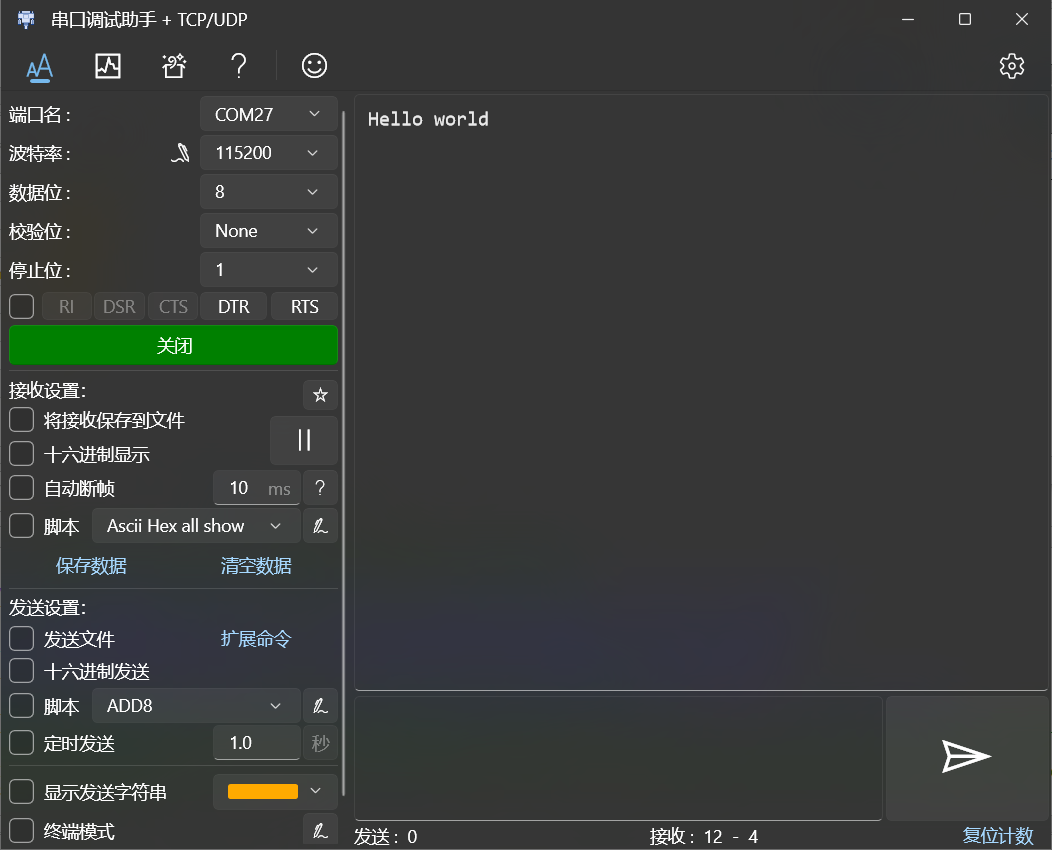
步进R1
该版本将EX拆分为两级,旨在大幅减少组合逻辑长度。
性能表现
在Cyclone IV E EP4CE15 速度等级C8平台上以激进性能方式综合布线后,LUT4占用为3,483,最大时钟为127.94Mhz(提升68%)。在Artix 7 XC7A50T 速度等级-3平台上以默认方式综合布线后,LUT6占用为1,700,最大时钟为248.13Mhz(提升119%)。对比给出的VexRISCV,频率已经超出7%,但综合面积超出了108%,指令执行速度低43%。